
Background
If you are not familiar with the Stingray Entity system you can find good resources to catch up here:- Stingray Engine Code Walkthrough #18 Entities
- Autodesk Stingray Blog: Building a Data-Oriented Entity System (part 1)
- Autodesk Stingray Blog: Building a Data-Oriented Entity System (Part 2: Components)
- Autodesk Stingray Blog: Building a Data-Oriented Entity System (Part 3: The Transform Component)
- Autodesk Stingray Blog: Building a Data-Oriented Entity System (Part 4: Entity Resources)
To accomplish this we added a “Property” system that Flow and other parts of the Stingray Engine can use which is optional for each Component to implement in addition to having its own specialized API. The Property System enables an API to read and write entity component properties using the name of component, the property name and the property value. The Property System needs to be able to find a specific Component Instance by name for an Entity, and the Entity System does not directly track an Entity / Component Instance relationship. It does not even track the Entity / Component Manager relationship.
So what we did was to add the Entity Index, a registry where we add all Component Instances created for an Entity as it is constructed from an Entity Resource. To make it usable we also added the rule that each Component in an Entity Resource should have a unique name within the resource so the user can identify it by name when using the Flow system.
In order for the Flow system to work we need to be able to find a specific component instance by name for an Entity so we could get and set properties of that instance. This is the job of the Entity Index. In the Entity Index you can register an Entitys components by name so you later can do a lookup.
Property System and Entity Index
When creating an Entity we use the name of the component instance together with the component type name, i.e the Component Manager, and create an Entity Index that maps the name to the component instance and the Component Manager. In the Stingray Entity system an Entity cannot have two component instances with the same name.Example:
Entity
- Transform - Transform Component
- Fog - Render Data Component
- Vignette - Render Data Component
For this Entity we would instantiate one Transform Component Instance and two Render Data Component Instances. We get back an InstanceId for each Component Instance which can be used to identify which of Fog or Vignette we are talking about even though they are created from the same Entity using the same Component Manager.
We also register this in the Entity Index as:
| Key | Value |
|---|---|
| Entity | Array<Components> |
The Array<Components> contains one or more entries which each contain the following:
| Components |
|---|
| Component Manager |
| InstanceId |
| Name |
Lets add the a few entities and components to the Entity Index:
entity_1.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | 13 |
| hash(“Fog”) | &render_data_manager_1 | 4 |
| hash(“Vignette”) | &render_data_manager_1 | 5 |
entity_2.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | 14 |
| hash(“Fog”) | &render_data_manager_1 | 6 |
| hash(“Vignette”) | &render_data_manager_1 | 7 |
entity_3.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | 2 |
| hash(“Fog”) | &render_data_manager_2 | 4 |
| hash(“Vignette”) | &render_data_manager_2 | 5 |
This allows Flow to set and get properties using the Entity and the Component Name. Using the Entity and Component Name we can look up which Component Manager has the component instance and which InstanceId it has assigned to it so we can get the Instance and operate on the data.
The problem with this implementation is that it will become very large - we need a large registry with one key-array pair for each Entity where the array contains one entry for each Component Instance for the Entity, not very efficient as the number of entites grow. There is no reuse at all in the Entity Index - and it can’t be - each entry in the index is unique with no overlap.
Here are some measurements using a synthetic test that creates entities, add and looks up components on the entities and deleted entities. It deletes parts of the entities as it runs and does garbage collection. The number entities given in the tables is the total number created during the test, not the number of simultaneous entities which varies over time. The entities has 75 different types of component compositions, ranging from a single component to eleven for other entities. The test is single threaded and no locking besides some on the memory sub system which makes the times match up well with CPU usage.
| Entity Count | Test run time (s) | Memory used (Mb) | Time/Entity (us) |
|---|---|---|---|
| 10k | 0.01 | 5.79 | 0.977 |
| 20k | 0.01 | 5.79 | 0.488 |
| 40k | 0.03 | 11.88 | 0.732 |
| 80k | 0.06 | 11.88 | 0.732 |
| 160k | 0.13 | 25.69 | 0.793 |
| 320k | 0.32 | 31.04 | 0.977 |
| 640k | 1.08 | 55.90 | 1.648 |
| 1.28m | 2.58 | 65.82 | 1.922 |
| 2.56m | 6.35 | 65.55 | 2.366 |
| 5.12m | 13.42 | 120.55 | 2.500 |
| 10.24m | 25.69 | 130.55 | 2.393 |
As you can see we start to take longer and longer time and use more and more memory as we double the number of entities and as we get to the larger numbers the time and memory increases pretty dramatically.
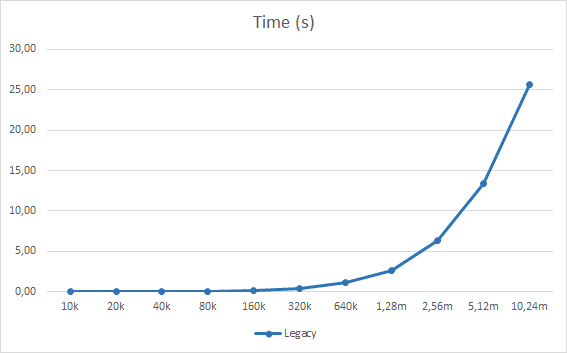

Since we plan to use the entity system extensively we need an index that is more efficient with memory and scales more linearly in CPU usage.
Shifting control of the InstanceId
The InstanceId is defined to be unique to the Entity instance for a specific Component Manager - it does not have to be unique for all components in a Component Manager, nor does it have to be unique across different Component Managers.The create and lookup functions for an Component Instance looks like this:
InstanceWithId instance_with_id = transform_manager.create(entity);
InstanceId my_transform_id = instance_with_id.id;
.....
Instance instance = transform_manager.lookup(entity, my_transform_id);The interface is somewhat confusing since the create function returns both the component instance id and the instance. This is done so you don’t have to do a lookup of the instance directly after create. As you can see we have no knowledge of what the resulting InstanceId will be so we can’t make any assumptions in the Entity Index forcing us to have unique entries for each Component instance of every Entity.
But we already set up the rule that in the Entity Resource, each Component should have a unique name for the Property System to work - this is a new requirement that was added at a later stage than when designing the initial Entity system. Now that it is there we can make use of this to simplify the Entity Index.
Instead of letting each Component Manager decide the InstanceId we let the caller to the create function decide the InstanceId. We can decide that the InstanceId should be the 32-bit hash of the Component Name from the Entity Resource. Doing this will restrict the possible optimization that a component manager could do if it had control of the InstanceId, but so far we have had no real use case for it and the benefits of changing this are greater than the loss of a possible optimization that we might do sometime in the future.
So we change the API like this:
Instance instance = transform_manager.create(entity, hash("Transform"));
.....
Instance instance = transform_manager.lookup(entity, hash("Transform")); Nice, clean and symmetrical. Note though that the InstanceId is entierly up to the caller to control, it does not have to be a hash of a string. It must be unique for an Entity within a specific component manager. Having it work with the Entity Index and the Property System the InstanceId needs to be unique across all Component Instances in all Component Managers for each Entity instance. This is enforced when an Entity is created from a resource but not when constructing Component Instances by hand in code. If you want a component added outside the resource construction to work with the Property System care needs to be taken so it does not collide with other names of component instances for the Entity.
Lets add the entities and components again using the new rule set, the Entity Index now look like this:
entity_1.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | hash(“Transform”) |
| hash(“Fog”) | &render_data_manager_1 | hash(“Fog”) |
| hash(“Vignette”) | &render_data_manager_1 | hash(“Vignette”) |
entity_2.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | hash(“Transform”) |
| hash(“Fog”) | &render_data_manager_1 | hash(“Fog”) |
| hash(“Vignette”) | &render_data_manager_1 | hash(“Vignette”) |
entity_3.id
| Name | Component Manager | InstanceId |
|---|---|---|
| hash(“Transform”) | &transform_manager | hash(“Transform”) |
| hash(“Fog”) | &render_data_manager_2 | hash(“Fog”) |
| hash(“Vignette”) | &render_data_manager_2 | hash(“Vignette”) |
As we now see the Instance Id column now contain redundant data - we only need to store the Component Manager pointer. We use the Entity and hash the component name to find our Component Manager which can be used to look up the Instance.
entity_1.id
| Name | Component Manager |
|---|---|
| hash(“Transform”) | &transform_manager |
| hash(“Fog”) | &render_data_manager_1 |
| hash(“Vignette”) | &render_data_manager_1 |
entity_2.id
| Name | Component Manager |
|---|---|
| hash(“Transform”) | &transform_manager |
| hash(“Fog”) | &render_data_manager_1 |
| hash(“Vignette”) | &render_data_manager_1 |
entity_3.id
| Name | Component Manager |
|---|---|
| hash(“Transform”) | &transform_manager |
| hash(“Fog”) | &render_data_manager_2 |
| hash(“Vignette”) | &render_data_manager_2 |
We now also see that the lookup array for entity_1 and entity_2 are identical so two keys could point to the same value.
Options for implementation
We could opt for an index that has a map from entity_id to a list or map of entries for lookup:entity_1.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]
entity_2.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]
entity_3.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_2 ], [ hash("Vignette"), &render_data_manager_2 ]
We should probably not store the same entry lookup list multiple times if it can be resused by multiple entity instances as this wastes space, but at any time a new component instance can be added or removed from an entity and its entry list would then change - that would mean administrating memory for the lookup lists and detecting when two entities starts to diverge so we can make a new extended copy of the entry list for the changed entity. We should probably also remove lookup lists that are no longer used as it would waste memory.
Entity and component creation
The call sequence for creating entities from resources (or even programmatically) looks something like this:Entity e = create();
Instance transform = transform_manager.create(e, hash("Transform"));
Instance fog = render_data_manager_1.create(e, hash("Fog"));
Instance vignette = render_data_manager_1.create(e, hash("Vignette"));
In this scenario we could potentially build a entity lookup list for the entity which contains lookup for the transform, fog and vignette instances:
entity_index.register(e, [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]);
But as stated previously - component instances can be added and removed at any point in time making the lookup table change during the lifetime of the Entity. We need to be able to extend it at will, so it should look something like this:
Entity e = create();
Instance transform = transform_manager.create(e, hash("Transform"));
entity_index.register(e, [ hash("Transform"), &transform_manager ]);
Instance fog = render_data_manager_1.create(e, hash("Fog"));
entity_index.register(e, [ hash("Fog"), &render_data_manager_1 ]);
Instance vignette = render_data_manager_1.create(e, hash("Vignette"));
entity_index.register(e, [ hash("Vignette"), &render_data_manager_1 ]);
Now we just extend the lookup list of the entity as we add new components. This means that two entities that started out life as having identical lookup lists after being spawned from a resource might diverge over time so the Entity Index needs to handle that.
Component Instances can also be destroyed, so we should handle that as well. Even if we do not remove component instances things will still work - if we keep a lookup to an Instance that has been removed we would then just fail the lookup in the corresponding Component Manager. It would lead to waste of memory though, something we need to be aware of going forward.
Building a Prototype chain
Looking at how we build up the Component instances for an Entity it goes something like this: first add the Transform, then add Fog and finally Vignette. This looks sort of like an inheritance chain…Lets call a lookup list that contains a specific set of entry values a Prototype.
An entity starts with an empty lookup list that contains nothing [], this is the base Prototype, lets call that P0.
- Add the “Transform” component and your prototype is now P0 + [&transform_manager, “Transform”], lets call that prototype P1.
- Add the “Fog” component, now the prototype is P1 + [&render_data_manager_1, “Fog”] - call it P2.
- Add the “Vignette” component, now the prototype is P2 + [&render_data_manager_1, “Vignette”] - call it P3.
The prototype registry will contain:
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
If you create another entity which uses the same Components with the same names you will end up with the same prototype:
Create entity_2, it will have the empty prototype P0.
- Add the “Transform” component and your prototype now P1.
- Add the “Fog” component, now the prototype is P2.
- Add the “Vignette” component, now the prototype is P3.
We end up with the same prototype P3 as the other entity - as long as we add the entities in the same order we end up with the same prototype. For entites created from resources this will be true for all entities created from the same entity resource. For components that are added programatically it will only work if the code adds components in the same order, but even if they do not always do this we still will have a very large overlap for most of the entities.
Lets look at the third example where we do not have an exact match, entity_3:
Create entity_3, it will have the empty prototype P0.
- Add the “Transform” component and your prototype is now P0 + [&transform_manager:Transform, “Transform”] = P1.
- Add the “Fog” component - this render data component manager is not the same as entity_1 and entity_2 so we get P1 + [&render_data_manager_2, “Fog”], this does not match P2 so we make a new prototype P4 instead.
- Add the “Vignette” component, now the prototype is P4 + [&render_data_manager_2, “Vignette”] -> P5.
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
P4 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"]
P5 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"] + [&render_data_manager_2, "Vignette"]
Storage of the prototype
We can either for each prototype store all the component lookup entries - this makes it easy to get all the component instance look-ups in one go at the expense of memory due to data duplication. Each entity will store which prototype it uses.- entity_1 -> P3
- entity_2 -> P3
- entity_3 -> P5
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
P4 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"]
P5 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"] + [&render_data_manager_2, "Vignette"]
Some of the entries (P2 and P4) could technically be removed since they are not actively used - we would need to temporarily re-create them as new entries with the same structure were added.
A different option is to actually use the intermediate entries by referencing them, like so:
P0 = []
P1 = P0 + [&transform_manager, "Transform"]
P2 = P1 + [&render_data_manager_1, "Fog"]
P3 = P2 + [&render_data_manager_1, "Vignette"]
P4 = P1 + [&render_data_manager_2, "Fog"]
P5 = P4 + [&render_data_manager_2, "Vignette"]
Less wasteful but requires lookup up in the chain to find all the components for an entity. On the other hand we can make this very efficient storage-wise by having a lookup table like this:
Map from Prototype to {base_prototype, component_manager, component_name}. The prototype data is small and has no dynamic size so they can be stored very effiently.
The prototype will add all the prototypes to the same prototype map and since the HashMap implementation lookup gives us O(1) lookup cost, traversing the chain will only cost us the potential cache-misses of the lookup. Since the hashmap is likely to be pretty compact (via prototype reuse) this hopefully should not be a huge issue. If it turns out to be, a different storage approach might be needed trading memory use for lookup speed.
Since the amount of data we store for each Prototype would be very small - roughly 16 bytes - we can be a bit more relaxed with unused prototypes - we do not need to remove them as aggressively as we would if each prototype contained a complete lookup table for all components.
Building the Prototype index
So how do we “name” the prototypes effectively for fast lookup? Well, the first lookup would be Entity -> Prototype and then from Prototype -> Prototype definition.A simple approach would be hashing - use the content of the Prototype as the hash data to get a unique identifier.
The first base prototype has an empty definition so we let that be zero.
To calculate a prototype, mix the prototype you are basing it of with the hash of the protoype data, in our case we hash the Component Manager pointer and Component Name, and mix it with the base prototype.
Prototype prototype = mix(base_prototype, mix(hash(&component_manager), hash(component_name)))
The entry is stored with the prototype as key and the value as [base_prototype, &component_manager, component_name].
When you add a new Component to an entity we add/find the new prototype and update the Entity -> Prototype map to match the new prototype.
So, we end up with a structure like this:
struct PrototypeDescription {
Prototype base_prototype;
ComponentMananger *component_manager;
IdString32 component_name;
}
Map<Entity, Prototype> entity_prototype_lookup;
Map<Prototype, PrototypeDescription> prototypes;
void register_component(Entity, ComponentManager, component_name)
{
Prototype p = entity_prototype_lookup[Entity];
Prototype new_p = mix(p, mix(hash(ComponentManager), hash(component_name)));
if (!prototypes.has(new_p))
prototypes.insert(new_p, {p, &ComponentManager, component_name});
enity_index[Entity] = new_p;
}
ComponentMananger *find_component_manager(Entity, component_name)
{
Prototype p = entity_index[Entity];
while (p != 0)
{
PrototypeDescription description = prototypes[p];
if (description.component_name == component_name)
return description.component_manager;
p = description.base_prototype;
}
return nullptr;
}
This could lead to a lot of hashing and look-ups but we can change the api to register new components to multiple Entities in one go which would lead to dramatically less number of hashing and look-ups, we already do that kind of optimization when creating entities from resources so it would be a natural fit. Also, we can easily cache the base prototype index to avoid more of the hash look-ups in find_component_manager.
Measuring the results
Lets run the synthetic test again and see how our new entity index match up to the old one.| Entity Count | Test run time (s) | Memory used (Mb) | Time/Entity (us) |
|---|---|---|---|
| 10k | 0.01 | 0.26 | 0.977 |
| 20k | 0.01 | 0.51 | 0.488 |
| 40k | 0.03 | 0.99 | 0.832 |
| 80k | 0.06 | 0.99 | 0.610 |
| 160k | 0.11 | 0.99 | 0.671 |
| 320k | 0.23 | 0.99 | 0.702 |
| 640k | 0.46 | 0.99 | 0.702 |
| 1.28m | 0.94 | 0.99 | 0.700 |
| 2.56m | 1.88 | 0.99 | 0.700 |
| 5.12m | 3.78 | 0.99 | 0.704 |
| 10.24m | 7.57 | 0.99 | 0.705 |
The run time now scales very close to linearly and is overall faster than the old implementation. Most notable is the win when using a lot of entities. Memory usage has gone down as well and the time/entity is also scaling more gracefully.


Memory usage looks a little strange but there is an easy explanation - the mapping from entity to prototype is using almost all that memory (via a hashmap) and the actual prototypes takes less than 30 Kb. Note that the old index uses the same amount of memory for the Entity to Prototype mapping.
Lets compare the graphs between the old and new implementation:
| Entity Count | Time New (s) | Time Legacy (s) | Memory New (Mb) | Memory Legacy (Mb) | Time/Entity New (us) | Time/Entity Legacy (us) |
|---|---|---|---|---|---|---|
| 10k | 0.01 | 0.01 | 0.26 | 5.79 | 0.977 | 0.977 |
| 20k | 0.01 | 0.01 | 0.51 | 5.79 | 0.488 | 0.488 |
| 40k | 0.03 | 0.03 | 0.99 | 11.88 | 0.832 | 0.732 |
| 80k | 0.05 | 0.06 | 0.99 | 11.88 | 0.610 | 0.732 |
| 160k | 0.11 | 0.13 | 0.99 | 25.69 | 0.671 | 0.793 |
| 320k | 0.23 | 0.32 | 0.99 | 31.04 | 0.702 | 0.977 |
| 640k | 0.46 | 1.08 | 0.99 | 55.90 | 0.702 | 1.648 |
| 1.28m | 0.94 | 2.58 | 0.99 | 65.82 | 0.700 | 1.922 |
| 2.56m | 1.88 | 6.53 | 0.99 | 65.55 | 0.700 | 2.366 |
| 5.12m | 3.78 | 13.42 | 0.99 | 120.55 | 0.704 | 2.500 |
| 10.24m | 7.57 | 25.69 | 0.99 | 130.55 | 0.705 | 2.393 |


Looks like a pretty good win.
Final words
By taking into account the new requirements as the Entity system evolved we were able to create a much more space efficient and more performant Entity Index.The implementation chosen here has focused on reducing the amount of data we use in the Entity Index at the cost of lookup complexity, I think this is the right trade-of, especially since it performs better as well. Since the interface for the Entity Index is fairly non-complex and does not dictate how we store the data we could change the implementation to optimize for lookup speed if need be.
This comment has been removed by the author.
ReplyDeletehttp://www.missmountabu.com/silvassa-escorts.html
Deletehttp://www.sexyhema.in/silvassa-escorts.html
http://www.rajkotescorts.in/silvassa-escorts.html
http://www.nayraescorts.com/ambaji-escorts.html
http://www.rajkotescorts.in/ambaji-escorts.html
Microsoft Office Setup is the full suite of Microsoft point of confinement programming that joins a mix of jobs, affiliations, and server like Excel, PowerPoint, Word, OneNote, Publisher and Access. Near to the working systems, these undertakings are Microsoft's key things that are everything seen as used programming on the planet. Microsoft Office Setup packages all the best programming that Microsoft passes on to the table.
ReplyDeleteVisit for more :- www.office.com/setup
Nice blog. I would like to share it with my friends. I hope you will continue your works like this. Keep up the excellent work. You have a magical talent of holding readers mind. It is something special which cant be given to everyone.
ReplyDeleteMcAfee antivirus software has been eliminating malware, viruses and other kinds of online and offline threats from affecting the performance of a computer
It has a wide range of programs and protection. To know more about McAfee antiviruses contact Mcafee activate, they will assist and provides the best solutions.
Nice blog. I would like to share it with my friends. I hope you will continue your works like this. Keep up the excellent work.
ReplyDeleteQuickbooks support has many features to run your small or medium sized business,it mainly help for accounting,payroll payments etc.
http://sexybindu.in/jodhpur-escorts.html
Deletehttp://www.nayraescorts.com/jodhpur-escorts.html
http://www.jaincy.com/jodhpur-escorts.html
http://sexyramya.in/jodhpur-escorts.html
http://www.mountabuescorts.com/jodhpur-escorts.html
thanks to give for informative Web Design Company In india
ReplyDeleteThe main choice for uploading torrents is the Pirate Bay web site. If your Internet Service Provider blocks thepiratebay. org, or you are unable to access it for whatever reason, only visit one of the Pirate Bay Proxy pages. You can have direct exposure to the mirror of The Pirate Bay and you can grab all the media material you need.
ReplyDeletehttps://bestdognamess.wordpress.com/2019/04/07/toy-dog-breeds/
ReplyDeletehttps://bestdognamess.wordpress.com/2019/04/07/different-types-of-dog-breeds/
https://bestdognamess.wordpress.com/2019/04/07/mans-best-friend-dogs/
https://dognamesinfo.blogspot.com/2019/04/big-dog-breeds.html
https://dognamesinfo.blogspot.com/2019/04/dogs-phisical-activity.html
https://dognamesinfo.blogspot.com/2019/04/choose-perfect-family-dog.html
https://dognames225.hatenablog.com/entry/2019/04/01/151733
I’m a financial manager and using QuickBooks for maintaining the accounting records of my business. I am very comfortable in using QuickBooks for the advanced functions. When my QuickBooks is not able to load the license data, I am experiencing QuickBooks error 3371. This error code is an annoying error, which is making me more annoying. I guess that these errors occur due to the installation problems on the desktop at the time of running QuickBooks. So I don’t have much experience to fix QuickBooks error 3371 as soon as possible. Your recommendation would be admired.
ReplyDeleteAlong with a user-based voting system and a very active user group, this website has a big advantage over other torrent sites that function as an index. Users may also submit requests for new torrents, and user accomplishments are highlighted on the achievement page encouraging further participation. The website is also available in about 45 languages, making it easy to navigate the material for non-English users. Their.so domain is suspended as a result of transferring to.to TLD. They provide api to get all Kickass Proxy Sites or torrents listed on the website. To quickly add these to the search engine list, Opensearch is also supported.
ReplyDeleteSeveral internet service providers are globally blocking the Pirate Bay, but our pirate bay proxy bay mostly hosted from Europe, Poland, Russia and few countries where online piracy is not strict, so pirate bay is easily unblocked and accessible from anywhere in the world, these thepiratebayproxy lists are very fast and 100 percent safe and can unblock piratebay. How do the pirate bay proxies work? The world has many ISPs, mostly isp can restrict for their countries only. There are also several countries allowing for torrents and piracy websites. And this piratebay proxy or pirate bay mirrors website hosted in unregulated countries with the country ip with port rotation can make your anonymous. Now block piracy website including unblocked pirate bay and login worldwide.
ReplyDeletePrinter setup is not a big task but sometimes user face technical issues due to lack of knowledge. HP Printer Wireless Setup helps you to print the documents from distance. There are different ways to connect a wireless printer to Wi-Fi router.
ReplyDeleteyou facing gmail not working? Is your Gmail is not working? Well, it won’t work properly until you don’t fix it. But how? Gmail is not something that you cannot fix without a technique’s help. Instead, after knowing the required and effective steps to solve the problems of Gmail you can fix it at your home.
ReplyDeleteyou facing gmail not working? Is your Gmail is not working? Well, it won’t work properly until you don’t fix it. But how? Gmail is not something that you cannot fix without a technique’s help. Instead, after knowing the required and effective steps to solve the problems of Gmail you can fix it at your home.
ReplyDeleteDo you want to start your new printing business? Are you seeking for the best quality uv printer price in india? If yes, then I had a best recommendation for you i.e. best and authorized uv printer supplier in india - PH UV Printer. It is the only authorized uv printer supplier who will provide you the best quality of uv printer along with the best prices. If you are interested and want to know more then you can easily get all the information from the official website of PH UV Printer. But if you want something entertaining along with this business then you can go for the best shayari website in hindi - shayari ka pitara from where you'll get the best and latest shayari for you and your family.
ReplyDeleteRexoxer
ReplyDeleteRexoxer
HP fax error 388 is a communication issue which usually occurs when the machine is not properly connected to the phone line. You can check the lines and connections if you continue to face hp fax error 388. Go through the following tests to perform a fax test-
ReplyDeleteü Go to control panel and click on ‘Fax’ and then select ‘Setup’
ü Click on ‘Tools’
ü Select ‘Fax Test’ and the printer will keep you posted regarding the status
ü You will then get a print of the requested test document which you can examine as per your convenience
This is how you can run a fax test if you are facing hp fax error 388. Get in touch with us if you require assistance.
We are a dedicated team of professionals and HP technicians who can easily troubleshoot the HP printer not printing problem. This error has many reasons starting from network connectivity issues to the printer software issues. One should always diagnose the problem from the basics rather than jumping to the advanced issues. Any early diagnosis would require to check and ensure the network connectivity, or checking the ink cartridges you can also reinstall the Cartridges after cleaning them. You should always download the HP Smart app as it can notify you the error with your printer. We follow all the diagnostic steps to clear the HP Printer not printing error, you can take our expert’s help to debug the issue.
ReplyDeleteLet’s hire the best Corporate Solutions Provider and grow your business at a fast rate. We are one of the reliable administrators who are highly admired among the people for our excellent services.
ReplyDeleteKickass Torrent is a torrent downloading meta-search website that became popular in 2009. Many torrent websites were on the brink of the shutdown so Kickass Torrent came and rescued many people and provided them with a forum to access torrents. We'll be debating Best Kickass Proxy And Best Kickass Torrent Alternatives 2020 in this post. Kickass Torrent now has a very wide user base with a hundred thousand users who contribute to distributing millions of files so far. Kickass Torrent also offers faster speeds, more storage, and special servers for registered or paid users, being on the list of top 3 torrent sharing websites.
ReplyDeleteKickass Proxy Sites | Kickass Proxy Sites
Such a wonderful information blog post on this topic Allassignment services provides assignment service at affordable cost in a wide range of subject areas for all grade levels, we are already trusted by thousands of students who struggle to write their academic papers and also by those students who simply want Physiology Assignment Help to save their time and make life easy.
ReplyDeleteyou can click “Sign in,” and it is not recommended to choose “Remember me” on shared devices. I hope you will be able to access your roadrunner webmail account.
ReplyDeleteStruggling with piles of assignment and unable to deliver at least one assignment and now looking for reasonable and reliable assignment and seeking help then hire Assignment Writer from SourceEssay.
ReplyDeleteEssay Deutsch
case study
online essay help
Online Essay Writer
When print anything, any type of Error Printing HP Problem may appear all of sudden. Due to the printer error, the print job gets stuck. To resume the printing process appropriately, follow the below-mentioned instructions:
ReplyDelete· Cancel the print jobs that is stuck in the queue
· Switch off your device and then restart it again
· Check the paper loaded in the tray. If the paper is torn, remove it from its place and load the stack of paper in a proper manner
These above are the common solutions of fixing any printer problems. So, apply correctly and get your issues resolved.
I just wanted to say that I love every time visiting your wonderful post! Very powerful and have true and fresh information. Thanks for the post and effort! Please keep sharing more such a blog. More Visit: Forgot AOL Password
ReplyDeleteThe bottom line is that she is a perfectionist for a reason. Each time quality adult service is delivered, the client feels more confident about making the right choice selection. This is why one is saying that hot females make you their passionate lover and this is just not possible from the other sources. Mount abu escorts in hotel
ReplyDeleteBasically, there are three different ways through which Yahoo account recovery
ReplyDeleteYahoo account recoverycan be done on an instant basis. The ways are none other than through phone number verification, security question answer mode, and alternate email authentication. In our blog we will guide you how to recover yahoo account and how to easily recover a deleted account.
http://www.vapiescorts.in/silvassa-escorts.html
ReplyDeletehttp://www.nayraescorts.com/silvassa-escorts.html
http://www.rajkotescorts.in/silvassa-escorts.html
http://sexyramya.in/silvassa-escorts.html
http://www.mountabuescorts.com/silvassa-escorts.html
http://sexybindu.in/silvassa-escorts.html
http://www.vapiescortsservice.in/silvassa-escorts.html
http://sexyramya.in/
ReplyDeletehttp://www.nayraescorts.com/aburoad-escorts.html
http://mountabuescort.in/
http://www.rajkotescorts.in/aburoad-escorts.html
http://sexybindu.in/
We at roadrunner support number service are experts in dealing with problems of this nature. Technical problems are our forte. Contact the roadrunner email support by calling +1-833-536-6219 or by contacting the email support.
ReplyDeleteRoadrunner email support
Very interesting blog. I’m most interested in this one. Just thought that you would know. thanks for sharing such an informative post with us! keep working like that its really helpful for us! for more details visit here: Download QuickBooks Password Reset Tool
ReplyDeleteGreat Information sharing .. I am very happy to read this article .. thanks for giving us go through info. Fantastic nice. I appreciate this post. More Visit: Hoarding Advertising Agency in Hyderabad
ReplyDeleteEven, to take advantage of the appropriate defence. When using this smart virus, prevent any risk of encountering the bug, you must Activate McAfee Antivirus as soon as possible through mcafee.com/activate and pick your subscription package according to your need
ReplyDeleteThis can be reached by clicking on the 'Forgot Username or Password' icon from the main roadrunner login page.
ReplyDeleteI was suggested this web site by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my trouble. You’re amazing! Thanks! for more information click here: Brother Printer Error Code 72
ReplyDeleteThis is awesome blog.
ReplyDeleteCloud Migration India
Nice piece of article. It was really useful. I want to show you a new step in the development of microgaming. These are cool no deposit slots. Here you can find over 30 different slots on any topic. Try this site. This is amazing.
ReplyDeleteMost of them are no deposit. There are starting bonuses at registration.8)
Roadrunner's webmail guarantees your e-mail security simply by using safe encryption for messages. Every message delivered from the sender to your host and from the host to the receiver is encrypted having a security authentication system thus making certain your email is private you can contact the email support between you and the receiver.Contact the Roadrunner Email Problem Support by calling on the number +1-833-536-6219 or.
ReplyDeleteHi, this is a nice blog thanks for sharing the Informative blog content. Now You can subscribe to our monthly plan of $7 and get access to unlimited Q&A, Textbook Solutions Manuals, and ask 50 questions. structural analysis teaches students the basic principles of structural analysis using the classical approach. The chapters are presented in a logical order, moving from an introduction of the topic to an analysis of statically determinate beams, trusses, and rigid frames, to the analysis of statistically indeterminate structures.
ReplyDeleteThanks for sharing with Us. If you facing any issues due Comcast email login can visit my web usaemailhelp.com or connect our highly experienced engineers Fix Comcast email login issues
ReplyDeleteI am a professionals developer with over 10 years of experience. Right now I am working with CFS, this company has expertise in providing Textbook solutions manual and Q and A answer, assignment writing help.
ReplyDeleteThanks for sharing this information with Us. I appreciate your Blog. If you facing any technical issues due to Canon printer i.e. not responding errors. why my printer not responding? or it is show error message, How to Fix Canon printer not responding errors on Windows or Mac?
ReplyDeleteIn case you're experiencing difficulty to pick enact card demand in the application, at that point you can utilize the Cash App email and the talk instrument to get your answers so you can eliminate the blunders. Furthermore, it's consistently judicious to execute the help offered by the tech help destinations to manage the issue.
ReplyDeleteThanks for sharing with Us. If you facing any issues due to Aol mail login and Aol email password reset can connect our highly experienced engineers can resolve your all query available 24/7 in the USA.
ReplyDeleteif you are searching for the best services for bike rental in kolkata so you are exactly there here you can find the best services for bike rentals. for more details you may visit our webiste https://justbike.in/
ReplyDeleteBike rental in kolkata
Usually I never comment on blogs but your article is so convincing that I never stop myself to say something about it. You’re doing a great job Man,Keep it up. Visit:- quickbooks online login | www.hulu.com/activate | Cash app login | www.youtube.com/activate
ReplyDeleteHello, guys Welcome to Escort in Thane, myself Dipti a young Independent Thane Call Girl staying alone in my flat from the past 9 months. I have a best dazzling smile and flirty personality also high personality VIP Call Girl in Thane. If you want more fun and enjoyment with me then directly contact me from Thane Escort Service and book me anytime on the best affordable rate.
ReplyDeleteReally very happy to say, your post is very interesting to read.I never stop myself to say something about it.You’re doing a great job. Keep it up. Visit:- Black Friday deals Walmart | Walmart Black Friday deals | Black Friday deals Walmart | Amazon Black Friday deals | black friday gaming laptop deals | Black Friday.
ReplyDeleteA good website is useful.
ReplyDeletedoreenbaran.com
lesterbarber.com
Welcome to My Blog
ReplyDeletechateaubriantvoltigeursfoot.com
stateronline.com
This comment has been removed by the author.
ReplyDeleteNice content thanks for sharing with Us. how to fix another computer using the printer can use some important steps to fix the issues firstly check your printer driver and operating system message and update it.
ReplyDeleteNice content! For email - Having any kind of technical issues due to Windstream email account login or sign in, can follow the on screen instruction via the best technical instructor to Fix windstream email login issue easily. anywhere in the US.
ReplyDeleteHey Guys, My name is Maya Bansal. I am a passionate and sensuous girl. I have lustrous eyes, rosy lips, charming face, well-shaped rounded milky boobs with attractive butts. I have a great personality with a hot and sexy figure. I am always waiting for your call. You will get a boundless fun with Enjoy City Escorts. I will give you some memorable and unforgettable moment. After taking the services with me you will feel more energetic than before. Escorts in City is always looking your way. So contact me as soon as possible to make your day better.
ReplyDeleteJhajjar Escorts ##
Jind Escorts ##
Kurukshetra Escorts ##
Kaithal Escorts ##
Rewari Escorts ##
Palwal Escorts ##
Nashik Escorts ##
Nagpur Escorts ##
Thanks for sharing with us. I appreciate your thought... I want to share info about road runner email, If you facing Fix roadrunner email login issue are caused due to various reasons such as bad internet connection, wrong account username and password, incorrect email configuration settings, or firewall or Antivirus interruption. To fix these issues you must first confirm the messages of the error.
ReplyDeleteLimited parts are generally returned into your Cash app balance promptly if the preferences were sent from the Cash app equilibrium or cash related balance. Regardless, if the fragment began with the charge card, by then markdown will be begun inside a couple of days. In case you fronting any issue here. By then contact Cash app customer service.
ReplyDeleteDiva Williams is a creative person who has been writing blogs and articles about cybersecurity. She writes about the latest updates regarding office setup and how it can improve the work experience of users. She articles have been published in many popular e-magazines, blogs, and websites like webroot.com/safe .
ReplyDeleteHello, guys, I am Maya Bansal a young Independent Call Girl in Udaipur and I am looking for the best side income nearby me. so nowadays I am working as Escorts Service in Udaipur. I have great and high personality and beautiful physical fitness as you like to see in me all the best qualities. If you want a secure relationship with me and great VIP services in the 5-star hotel room so please tell me I will managing full secure and safe a luxury hotel room because there have my many friends of identity works in a 5-star hotel in Udaipur. If you want more information about me so please contact me direct Escorts Service in Udaipur.
ReplyDeleteJohn Peter is a creative person who has been writing blogs and articles about cybersecurity. He writes about the latest updates regarding office setup and how it can improve the work experience of users. He articles have been published in many popular e-magazines, blogs, and websites like office.com/setup .
ReplyDeleteZetor tractor parts - We have wide range of tractor and auto spare parts Catalog for Tractor Clutch Parts, Tractor Brake Parts,Tractor Engine Parts, Hydraulic Lift Parts, Tractor Steering Shafts, Rear Axle & Differential Parts, Hydraulic Pumps, Transmission Parts, Sector Shafts and other Parts. We are your source for Genuine OEM parts at very effective rates. We offer wholesale pricing on all the products featured on the Parts
ReplyDeleteCash app accounts can be used personally and as a business as well. Incidentally, prior to going to use Cash app accounts as a business, you have to have to create a personal account. After that, go for the profile image, and starting there change the personal account to a business account. If you still any solicitations, at that direct continue toward speak to a Cash app representative. https://www.monktech.us/cash-app-customer-service-phone-number.html
ReplyDeleteHello, Gentlemens if you are looking for a high-class Call Girl in Almora, with a lot of fun and hot real Girlfriend experience here I am !!! I'm your Angel Only for serious Gentlemen who want quality Bageshwar Escorts Service and who loves to enjoy.
ReplyDeletehttps://ctrlr.org/forums/users/stuti002/
ReplyDeletehttp://www.forum.konferencje.com/profile.php?mode=viewprofile&u=101174
ReplyDeletehttp://forum.9dots.de/profile.php?mode=viewprofile&u=11929
ReplyDeletehttp://80scartoons.net/forum/profile.php?mode=viewprofile&u=28172
ReplyDeletehttp://www.effecthub.com/user/1847259
ReplyDeletehttp://www.escalade-alsace.com/forum/profile.php?mode=viewprofile&u=9079
ReplyDeletehttps://torgi.gov.ru/forum/user/profile/1306366.page
ReplyDeletehttp://www.authorstream.com/stuti002/
ReplyDeletehttp://tale-of-tales.com/forum/profile.php?mode=viewprofile&u=56021
ReplyDelete
ReplyDeletehttp://phanteks.com/forum/member.php?424638-stuti002
You get teh full information is one of teh best thing is that you love you get full information related to site that mean that you love the content o fthe site https://gamense.com/mobile-legends-mod-apk/
ReplyDeleteNow the mean you all the people are leave that you syuck the people are love https://modsapkstores.com/panda-gamepad-pro-apk/
ReplyDeleteWhen you requirement of the content of teh lover at that mean you loev that you love https://modapkdone.com/human-fall-flat-mod-apk/
ReplyDeleteSo many many peopel are worries about this topci of the content of the site knowldege https://modapkstores.com/tr-vibes-mod-apk/
ReplyDeleteLove are lover with me and get the full information related the conetent of teh site which is best of teh site https://trickytraps.com/hotstar-premium-apk/
ReplyDeleteWhich love which love the best content f teh iste which is best for you me and need to learn of teh site Click here
ReplyDeletehttps://www.apsense.com/user/stuti002/contactinfo
ReplyDeletehttps://www.smashwords.com/profile/view/stuti002/
ReplyDeletehttps://www.snupps.com/stuti002/
ReplyDeletehttp://www.folkd.com/user/stuti002/
ReplyDeletehttp://uid.me/shar_stuti002#
ReplyDeletehhttps://itsmyurls.com/stuti002
ReplyDeletehttps://ignitiondeck.com/id/dashboard/?backer_profile=79267
ReplyDeleteExcellent article. Thanks for sharing with us. Looking for Mod Apk Latest Version For Android can visit this link https://sites.google.com/view/modapkstores/home
ReplyDeleteThis is nice thankyou. Looking for Mod Apk Latest Version For Android can visit this link
ReplyDeletehttp://modapkstoress.jigsy.com/
Thanks for sharing with us such a mind-blowing post. Looking for Mod Apk Latest Version For Android can visit this linkhttps://modapkstoress.hatenablog.com/
ReplyDeleteI think this is engaging and eye-opening material. Feeling Sleep difficulty???? visit this link to Know more.
ReplyDeletehttp://ambienoralbuy.mystrikingly.com/
I am really impressed with the information you provide in your post. Facing Sleeping disability???? Visit here.
ReplyDeletehttps://spotifybhai90444.wixsite.com/ambien
Thanks for sharing with us. To know more about CBD Oil Click here.https://yourpharma360.tumblr.com/
ReplyDeleteThanks for sharing. One time Solution for sleeping disability visit this link
ReplyDeletehttps://yourpharmacy360.blogspot.com/
Netflix Phone Number:- Netflix offers a customised streaming service that allows customers of the organisation to watch movies and TV shows ("Netflix content") streamed to some Internet-connected TVs, computers and other devices over the Internet ("Netflix ready devices"). These Terms of Use regulate the use of the company's service by the consumer. The Netflix membership of the client will continue until terminated. To use the Netflix service, the website user must have Internet access and a ready-to-use Netflix system, and must have one or more payment methods to www.netflix.com. A variety of membership plans may be provided by Netflix, including exclusive promotional plans or memberships offered by third parties in accordance with the provision of goods and services of their own. Some subscription plans which have various requirements and restrictions that will be disclosed at the sign-up of the customer or in other correspondence made available to the customer.
ReplyDeleteI am Nikita Rawat an independent female Escort in Chandigarh. You can call me if you want best girlfriend experience without any boundaries. Just call me at once and take my Escorts service In Chandigarh and feel the heaven. we can provide good behavior and good knowledge about Excellent sex experience call girls in Chandigarh. they can fulfill phys.
ReplyDeletehttps://www.akshitasen.net/chandigarh-escorts.html
Hi, I read your post. It is very graceful or informative information. Thanks for sharing your efforts with this post.
ReplyDeleteIf you want to easy to install and setup QuickBooks Desktop Pro, then you can take help from our professionals. Our team provides best-notch solutions related to your issues and you also dial our QuickBooks Toll-free number and easily resolve your issues at any time.
We at Acadecraft provide different types of Simulation-based dialogue design, which includes simple simulations, complex simulations, one-shot simulations, learn-by-example simulations, and microworlds. Moreover, our clients come from different industries, which include service providers, marketing industries, ed-tech companies, and manufacturing.
ReplyDeleteDialogue Simulation Services
Proceed to your own Account page (sign into if motivated ) and search to your Watch Hulu in Your Own Devices department, or go right into hulu.com/ / trigger . Input that the exceptional code that's displayed on your television screen and over 30 minutes or so that you ought to be logged into.
ReplyDeletewww.hulu.com/activate
www.hulu.com/activate
www.hulu.com/activate
www.hulu.com/activate
www.hulu.com/activate
www.hulu.com/activate
Quicken error OL–294–A is an account update error that occurs due to temporary server issues or invalid login credentials. Get the easy steps to resolve here.
ReplyDeleteMohali Escorts ||
ReplyDeleteMorbi Escorts ||
Munirka Escorts ||
Mussoorie Escorts ||
Nagpur Escorts ||
Nainital Escorts ||
Navi Mumbai Escorts ||
Nerul Escorts ||
Noida Escorts ||
On the site, head to a Amazon Prime App, or, even if there isn't it download it directly in the program shop or play with store. Open the program and then goto the sign-in alternative. You may obtain an amazon code, then see www.amazon.com/mytv and input amazon activation-code onto your smartphone or notebook. Now, key in the code and then go through the input option. You may get a notification in your own television. Love bingewatching your favourite shows.
ReplyDeleteamazon.com/mytv
amazon.com/mytv.com
www.amazon.com/mytv code
www.amazon.com/mytv enter code
Lately, you will find over 90,000 shows and movies available on the Amazon Instant Video, a particular offer by the Amazon Prime services. You are able to stream all of them via your compatible and registered SMART-TV or video apparatus. Whatever your preferevnces are, so you're able to trust Amazon Prime Videos to truly have some thing to youpersonally.
ReplyDeleteprimevideo.com/mytv
www.amazon.com/mytv enter code
amazon.com/mytv
www.amazon.com/mytvcode
Again, to enroll your own apparatus, you'll want to show your device, down load the prime video program, enroll your apparatus either as a brand new individual or existing user together with your specific 5-6-character verification code, and then sign directly to a amazon prime accounts to begin enjoying the enjoyable content and one of a kind streaming experience which can be found on the platform.
ReplyDeletewww.primevideo.com/mytvamazon.com/mytv.com
www.amazon.com/code
www.amazon.com/mytv activate
Suppose you're on the lookout for the ideal device for the Amazon Prime Video. If that's the circumstance, you ought to think about that the Amazon Fire-TV Family, settop boxes, SMART-TV, bluray player, Game Consoles, Fire Tablet, i-OS mobile or tabletcomputer, Android apparatus, and Google Chrome cast.
ReplyDeletewww.amazon.com/mytv
www.amazon.com/mytv
www.amazon.com/code
ReplyDeleteGreat Job! This is so wonderful and informative post. Thanks for sharing with us.
Whenever you install HP software on your device/computer, an error occurs that says "HP Driver Install Error 1603" when you attempt to install several programs simultaneously, such as system updates, startup services, or other installs then you may face this error. By performing some simple steps, get rid of this blunder. Contact HP Support Experts for any issues with the steps or any other problems. They're going to help you with your problems in the best way.
Welldone Post! Thanks for giving me this information. I appreciate your hard work and your skills.
ReplyDeleteAre you looking for easy solutions to Resolve AOL Mail Login Problems occurs while user sign-in to your AOL account? AOL Email Login Problems become when you enter incorrect information, your account has been blocked, or you have forgotten your password and other errors. Often, problems with AOL Mail Login can be caused by a password problem. There are common reasons for login problems such as not being able to validate the login page, the account has been temporarily closed, the browser does not respond to the query, the server may not respond to the query in the region. You can contact our email experts to help you with your problems in a potential way to Resolve AOL Email Login Issues.
The Cash app is always focused on providing smooth money transferring service to the customers. Nowadays customers can also send money from apple pay to cash app account. For which they have to follow a list of steps. We suggest our users contact the customer support team and talk to our defy professionals. They will help you to complete this transfer with the easiest steps.
ReplyDeleteInfrequently you may experience tech glitches that may achieve the mistake of activate Cash App card. To fix the failure you can use the researching courses of action that are open in the tech help regions. You can in like manner suggest the application's help site and interface with the customer care.
ReplyDeleteThe Cash app is always focused on providing smooth money transferring service to the customers. Nowadays customers can also send money from apple pay to cash app account. For which they have to follow a list of steps. We suggest our users contact the customer support team and talk to our defy professionals. They will help you to complete this transfer with the easiest steps.
ReplyDeleteFor moving an instalment you need to have the application connected to your ledger so you can add cash to the application when required. Yet, in the event that the application's record isn't connected and because of that Cash App transfer failed circumstance happens, at that point you can take the assistance of technical support destinations and go through their help to effectively set a connection between the application and the bank. You can likewise contact the assistance group.
ReplyDeleteHyper-threading technology: Hyper-threading is a technology that multiple threads to be executed on a single threaded core. If you are from the tech field, you must have ready about “How screwed is Intel without hyperthreading.” And the Intel Core i9 is the only Intel processor series that comes with this technology.intel core laptops
ReplyDeleteBeing one of the leading printer brands, who says that it cannot encounter technical glitches? If the user triggers any technical bug then he can take our Brother Printer Support Number Australia. Offering satisfy customer technical support services is our top-most preference. Brother Printers support services are specially designed, considering the printing need of the clients.
ReplyDeleteYou are so interesting! I don’t believe I’ve truly read through anything like that before. So wonderful to discover another person with a few unique thoughts on this issue. Seriously.. many thanks for starting this up. This website is something that is required on the internet, someone with a bit of originality!
ReplyDeleteStock Analyzer
Quotesmystatus is the best website for quotes & status about love, success, funny, happy, sad, romantic and motivational etc. that will be downloaded quotes images and shared easily from our website. The best quote collection of inspiring, motivational quotes and funny memes about love, life, friendship, change and heartbreak for me and there is many quotes to share your partner and friends or family, Quotes, Love Quotes, Life Quotes, Vitamin B12 Sources in Hindi
ReplyDeleteEnsure wi fi is On on your apparatus settings. Ensure that your device is linked to your own Xfinity system and perhaps not that the Xfinity wi fi system or yet another wireless system by injury. Restart your device, start the Xfinity Stream program if the program admits you are currently attached to a own network.
ReplyDeletexfinity.com/authorize roku
xfinity.com/authorize
wwww.xfinity.com/authorize
xfinity.com/authorize
xfinity.com/authorize roku
darthvadertv.com
ReplyDeletedarthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
ReplyDeletedarthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
ReplyDeletedarthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
darthvadertv.com
In some cases, there may be an issue in dispatching the application and that may thusly cause Gmail error 400. Considering, you can utilize the assistance that is made open to you by utilizing the tech help social event or you can interface with the assistance spot and use the assistance that is passed on as FAQs.
ReplyDeleteThe markdown elective is perhaps the most epic highlights of the application., by then you can answer to get your cashback. On the off chance that that doesn't resolve the issue, by then call Yahoo support to find uphold. In addition to that, video assistance in the form of galleries on Youtube is available to root out any error.
ReplyDelete
Very good! thank you so much! Thank you for sharing this post thanks for sharing with us
ReplyDeleteMicrosoft Office Home & Student for Mac 2016 (Lifetime License)
McAfee Total Protection 2020 ( 1 Year/ 1 Device)
If you are facing any issues with your Brother Printer, then these troubleshooting tips may assistance you. Follow the below listed fast tips or connect with our high expertise technicians on Brother Printer Support Number Australia to resolve your problem over phone.
ReplyDeletenice post and thanks for sharing
ReplyDeletemobile app development company| web app development company|cloud app development company|saas app development company|custom mobile app & web app development company|mobile app and web app maintenance services|seo services | seo company|digital marketing company|Paid marketing services | ppc service providers
You gave a stunning once-over of blog remarking Sites, from these complaints, we are getting sufficient backlinks, Almost every single site was having a decent domain also as page esteem.BellSouth email Login not working issue with these investigating steps. Expectation you discover these means helpful and ready to address the question. On the off chance that you can't reset BellSouth email Login secret phrase.
ReplyDeletefor more info:- https://sites.google.com/view/bellsouthemailloginpage/
We can compose your homework for each subject which you study. This is ascribed to the way that we have recruited scholarly composing specialists from assorted fields of study to draft your homework of different subjects which structure a piece of your scholastic course. Therefore, you can submit a request for homework help with us, irrespective of the sort of your subject. assignment help australia , assignment help uk
ReplyDeleteSurrounded by worries and stress? Your relief mantra is here! Crazy For Study brings optimum solutions to ease your academic burden. It’s cost effective, accredited and recommended by best brains worldwide! Bring wealth of knowledge at your home today, and get promising results!
ReplyDeleteGet intermediate accounting 8th edition spiceland solutions manual by Crazy For Study and received excellent results so far.
A best stepwise guide to study Engineering and solutions to textbook problems.
Thanks for sharing this information.
ReplyDeleteIf you are facing CenturyLink.net email problems, then don't worry. We can help you in fixing these problems. We will provide you instant fixes to solve this issue and you can smoothly use CenturyLink.net email.
Thank you for this brief explanation and very nice information. This post gives truly quality information. hope to see you again. I find that this post is really amazing.
ReplyDeleteDLF Share Price
You provide very useful data.
ReplyDeleteThis post give me lots of advise it is very useful for me.
Very vast and nicely explained.
Here I am sharing my website Kindly go through it http //ij.start.canon setup.
"Astrologer N.K Shastri Ji is acclaimed for his visionary and accurate astrologers and successful astrological remedies. His astrological measures are mainly famous in many urban areas of India and abroad. With intensive study and vast involvement with Vedic astrology, N.K Shastri Ji has acquired astrological knowledge to understand and deal with various life issues.
ReplyDeleteLet it be any problem of life-related to Late Marriage, Love Marriage, Love Affairs, Divorce, Black Magic, Kundli Making, Inter Caste Love Marriage, Breakup, Career, Business, Get Lost Love Back, Dua For Love, Foreign Trip, etc. I provide transparent and effective advice to overcome or handle difficult situations in life by using my astrology skills and experience. I only believe in the best excellence of the consultation. Anybody from anywhere can reach out to him via both Phone & Whatsapp (+91-9910253443) and Mail (consultbestastro@gmail.com)."
Husband Wife Problem Solution in India
Husband Wife Problem Solution in Bangalore
Get Your Love Back in Delhi
Love Marriage Specialist in Varanasi
Love Marriage Specialist in Uae
Vashikaran Specialist in Dubai
Love Marriage Specialist in Hyderabad
Vashikaran Specialist in Bhopal
Love Vashikaran Mantra
Desertlocksmithaz is a locksmith company and 15 years of experience in the locksmith industry. We have provided multiple types of Locksmith services like car locksmith service, residential locksmith services, motorcycle key locksmith and more. We Provide 24*7 service in Pheonix, Scottsdale, and Paradise Valley.
ReplyDeleteIf you could just envision the number of students who are whining about confounded assignments requiring a lot of time and nerves. Here, each student can purchase a Research Paper Help and thusly, make his/her academic cycle run smoothly. Your request will be cultivated by the best degree masters. We have dedicated research paper helpers who are always ready to give you impressive service in the best and possible timeframe.
ReplyDeleteVery creative blog!!! I learned a lot of new things from your post. It is really a good work and your post is the knowledgeable.if you are on the lookout for Comcast Phone Number.So, here you can get all details for the same
ReplyDeleteUttam Nagar Escorts |Pitampura Escorts |Kapashera Escorts |Ashram Escorts |Mukherjee Nagar Escorts |Sarojini Nagar Escorts |Vivek Vihar Escorts
ReplyDeleteEast of Kailash Escorts |Chanakyapuri Escorts |RK Puram Escorts |Munirka Escorts |Vasundhara Escorts |Kaushambi Escorts |Vaishali Escorts |Indirapuram Escorts
ReplyDeleteSarita Vihar Escorts |Lajpat Nagar Escorts |Vasant Kunj Escorts |Laxmi Nagar Escorts |Rohini Escorts |Aerocity Escorts |Karol Bagh Escorts
ReplyDeleteGurgaon Escorts |Malviya Nagar Escorts |Paharganj Escorts |Mahipalpur Escorts |Kalkaji Escorts |Dwarka Escorts
ReplyDeleteSaket Escorts |Ghaziabad Escorts |Connaught Place Escorts |Greater Noida Escorts |Nehru Place Escorts |Punjabi Bagh Escorts
ReplyDeleteWay cool! Some very valid points! I appreciate you penning this article and also the rest of the site is really good.
ReplyDeleteRoadrunner mail support
Gentleman, Call now Jamshedpur Escorts Service, here we have many Independent girls, VIP Call Girls, college girls, models, etc are working as Female Escorts in Jamshedpur for the past 2 years in your hometown. Our all ladies are well-educated decent honest and fully cooperative behave and provide endless physical satisfaction and erotic massage during relation and many additional services give you more pleasure. Our Jamshedpur Call Girls service is 24 hrs available in Jamshedpur. Just send your live location we will drop your dream girls under 30 min in your area. Guys If you are a Gentleman and looking for a dynamic physical Escorts Service in Jamshedpur. We present here many gorgeous and full attractive high personality beautiful young Jamshedpur Call Girls at your place your Our girls are well trained and full cooperative a special service during relationship on the bed sensual massage service rubbing nide shower body to body massage x massage Please contact us for your pleasure and get more details about girls from Jamshedpur Escort Service.
ReplyDeleteChange Your Mood For Better Sex Life with Delhi Escorts
ReplyDeleteBest Delhi Escort Service for cheap erotic dates with pretty young sex girls who will spice up your life! Our local Delhi escort service can provide you with trustable recommendations.We are sure our Delhi Call Girls ladies are even hotter and sexier than your crush. http://www.kacchikaliyaan.co.in/delhi-escorts-2/
Delhi Escorts
Escorts Service in Delhi
Do you want to grow your business online we provide you world best digital marketing services at the lower cost. our digital marketing agency hold your business as the way you want we even have attractive packages of digital marketing solutions our services are enriched with quality we focus on to build your business into a brand.
ReplyDeleteVisit Our Website To know About The Digital Marketing Services:- Digital Marketing Services
Are you searching for a Uber Corporate Office Phone Number? so then this will be very helpful for you to get some information on uber corporate headquarters mailing address.
ReplyDeleteNice post
ReplyDeleteGandhi medicos has all types of medicines such as cancer medicines, hiv medicines, hepatitits b medicines
, hepatitits c medicines and many more. All the medicines are available at affordable prices.
If you are a non-verified Cash app user, you must provide your information to make your account verified first. Once you verified your account, you should easily invest in stock market with the help of your cash app. For more information about How To Buy And Send Bitcoin With Cash App, contact the experts right now.
ReplyDeleteOn a very basic level, the Cash app goes with the Visa check card which you can use to purchase things and organizations in the USA with no additional charge card or Mastercard. Close by this, you can make a Cash app dispute if you make a trade with this card. A vendor can take a constraint of 10 days to make your rebate. In case you have any requests, thusly, by at that point, reach us to fix all.
ReplyDeleteThanks for the information about the entity index. However When you need information related to bank of america headquarters address , Bank of America New York, Bank of America corporate headquarters mailing address, etc., you should connect with JustCOL.
ReplyDeleteHi James this side, Thanks for sharing this very useful amazing and informative articles. if you want to get the information about Justfly Contact Phone Number. So, here you can get all details for the same
ReplyDeleteZucol provides finance & restructuring services. Restructuring is a productive solution to help your business eliminate financial problems & improve business liquidity.
ReplyDeleteAre you searching for ui ux design | ui/ux designers service in India then you can check out our website The design trip. Everyone gets the best service at very low cost. For more information visit our website.
ReplyDeleteYou can access millions of study documents homework answers at our Desklib online library. Here student can ask question regarding any subject and get solution to it.
ReplyDeleteYour post surely hits the right emotion. Kudos for the beautiful write-up. If you are struggling to play exceptionally well with your words while writing your academic online homework help in USA, you can get in touch with the committed writing and editing team of the Myassignmenthelpau platform at a time that suits you best.
ReplyDeleteAmazon Prime is a paid membership to www.amazon.com/mytv that gives you admittance to a huge scope of administrations: free quick conveyance, limitless video web based, selective admittance to bargains, among others. It permits its endorsers limitless spilling of films and TV shows. The vast majority of the substance accessible on Amazon Instant Video can be transferred free of charge on with an Amazon Prime membership. You can produce the actuation code on your gadget with the assistance of Prime Video application. With this data convenient, you can get a novel code and enact their gadgets in under one moment.
ReplyDeletewww.amazon.com/mytv
primevideo.com/mytv
amazon.com/mytv
amazon.com/mytv
digital marketing agency
ReplyDeletedigital marketing services
seo companies
McAfee is the leading Antivirus Security software, which provides complete protection from the virus in the user’s devices- applications, software, and the assurance of safety browsing. McAfee Antivirus brilliant features, which has impressed all the computer user’s all over the globe for decades and makes it ahead of all its competitors. Some of the features of McAfee Antivirus are-
ReplyDelete▪ Provides a free customer-identity protection.
▪ Easy and smooth access to mobile devices.
▪ Provides compatibility on different platforms.
▪ On the regular basis, alternate scanning and detection are done.
mcafee.com/activate
The development of online accounts like Cash App has eased the transaction processes for the People. But the unexpected tech issues obstruct them badly. Therefore, they need to contact Cash App customer service professionals to share their concerns and get an instant solution. Cash App users may connect to them with the phone call as it is the most suitable way to connect to them. Cash App Refund
ReplyDeleteI am Dipti Kaur a Call Girl in Andheri. I am working at Escorts Service in Andheri. To book me a call at our agency and after confirmation, I am available to you at your said place and time. You can fuck me in many sexual positions and you can also do oral sex with me I love to do oral sex. I am the most demanding Female Escort in Andheri. I am Neena a Call Girl in Andheri working at Escorts Service in Andheri. You can book me at our agency and enjoy with me at your said place and time. You can fulfill all your sexual needs with me without any extra charges. I can also do striping for you to make you more excited. Welcome to Escorts Service in Andheri. Our Female Escorts in Andheri are very young and energetic. They know how to behave with clients and how to give them full satisfaction. Dipti Kaur is one of our youngest Call girls in Andheri. she is so cute and will give you the best girlfriend experience. To book her, call our agency.
ReplyDeleteMumbai Escort Service offering hot greater Mumbai escorts. for meet me VIP escorts in Mumbai, online call girls in Mumbai and independent call girls Mumbai.
ReplyDeleteindependent Escort in Mumbai
Mumbai Escort Agency
Worli independent Escort
Colaba independent Escort
Mumbai Escort Service offering hot greater Mumbai escorts. for meet me VIP escorts in Mumbai, online call girls in Mumbai and independent call girls Mumbai.
ReplyDeleteEscort Service Mumbai
Escort in Mumbai
Chinchpokli independent Escort
Lokhandwala independent Escort
Very nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts In any case I’ll be subscribing to your feed and I hope you write again very soon good suggestions about blogging thanks a lot you give nice information
ReplyDeleteamazon.com/mytv
primevideo.com/mytv
amazon.com/mytv login
ReplyDeleteVery nice post. www.amazon.com/mytv I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts In any case I’ll be subscribing to your feed and I hope you write again very soon good suggestions about blogging thanks a lot you give nice information
I really enjoyed this information.
ReplyDeleteThis post give me lots of advise it is very useful for me.
Print pages quickly with this Canon PIXMA setup google print color inkjet wireless all-in-one printer, which also copies and scans for space-saving productivity.
digital marketing agency
ReplyDeletedigital marketing services
seo companies
social media marketing agency
Are you looking for interjet headquarters address. If so then this will be very helpful for you to get some information on interjet corporate headquarters. If you want to know about more then visit interjet corporate headquarters.
ReplyDeleteReally informative and inoperative, Thanks for the post and effort! Please keep sharing more such blog.if you want to get the information about Turkish Airline Nigeria Abuja Office. So, here you can get all details for the same
ReplyDeleteThanks for sharing all this information here on this page.
ReplyDeletehulu activate
hulu.com activate
Very very informative one .. Thanks for sharing amazing post …Keep posting like this. I appreciate you a lots and please keep it up.if you are on the lookout for Booking Flights Through Hopper. So, here you can get all details hopper flights booking
ReplyDeleteWhat good information, I like all your blogs. You are fine. Thanks to the administrator. Hello, I'm James Williams. Welcome to the Turkish Airline Nigeria Office. Our team of travel agents is prepared to help you on the phone you’ll rest assured we’re with you each step of the thanks to confirm your vacation is flawless.
ReplyDeleteIf you are searching for frontier flight cancellation policy, frontier airlines refund policy, fee find out here. If you want to search frontier cancellation policy then this post would be helpful for you.
ReplyDelete
ReplyDeleteThanks for sharing this information. Really informative site. Thanks for the post and effort! Please keep sharing more such blog. If you want to get the information about emirates cancellation policy. So, here you can get all details for it emirates cancellation policy or emirates flight cancellation
WWW.AMAZON.COM/MYTV | AMAZON Activation-code | AMAZON MY TV Let's speak about the primevideo.com/mytv enter code. For those who are in possession of a valid Amazon prime video account using an active subscription this informative article will lead you on what best to enter Amazon prime video manipulation code on primevideo.com/mytv input code.
ReplyDeleteamazon.com/mytv
amazon.com/mytv
amazon.com/mytv
amazon.com/mytv
mytv
Thanks for Posting Such a Nice blog. Keep updating Us in Future
ReplyDeleteFor More Relevant Information Please Visit
React Native or Flutter
Hi, I'm Chris Smith A blogger and Review writer From New York. Today I'm going to tell you about one of my favorite websites coupon2deal, where you can get great coupons and deals for free.
ReplyDeleteAmazon Promo Code
H&R Block Coupon
Macy's Coupons
DOWNLOAD THE AMAZON PRIME VIDEO APP FOR ANDROIDOne which just Amazon videos on your own Android, you will need to down load and put in the Amazon Prime Video app. Here is how:
ReplyDeleteamazon.com/mytv
amazon.com/mytv
amazon.com/mytv
www.amazon.com/mytv
amazon.com/code
Nice content thanks for sharing with Us. I appreciate your knowledge! If you are facing any issues due to CenturyLink email server setting which SMTP, POP3 and IMAP follow this post can help you all
ReplyDeleteThe station activation steps to build the Twitch television activation-code really are fairly easy. Simply visit the browser and then key in Twitch television Publish , and as soon as you've finished filling at the credentials in every single area, you may be re directed into the'Publish' button. No dependence on any other outside application or internet site, only an email address, password, and also a couple more credentials for enrollment. If you have a merchant account, then you may even make a brand new account and follow the display directions.
ReplyDeletetwitch.tv/activate
twitch.tv/activate
pluto.tv/activate
pluto.tv/activate
trakt.tv/activate
amazon.com/redeem check balance
What an interesting blog. In case, you need to get yourself a good deal on frontier cancellation policy then take a tour at frontier refund policy. You won’t be disappointed.
ReplyDeleteWhat an interesting blog. In case, you need to get yourself a good deal on Air France bookings then take a tour at Air France Manila Office . You won’t be disappointed.
ReplyDeleteReally happy to say that it's an amazing post to read and learn something new, I always come to know about something unique.
ReplyDeleteACP sheet printing machine
Wallpaper printing machine
PVC door printing machine
Cash App Sign up > If you are facing any trouble while log in then you need to read this blog. We will give a complete guide on how to login to the Cash App and give you tips to fix login errors. We are here to assist you and give detailed information on the cash app login error, can’t log in to the cash app.
ReplyDeleteCash App Sign up
Its my great pleasure to visit your blog and to enjoy your great posts here.
ReplyDeleteas all of them make sense and are very useful.
In case if you have any queries and to solve your troubles just check into my websites or blogs to resolve your problems.
We are providing online support to your printer.
The dreaded canon.com/ijsetup Error on your Canon Printer usually indicates that the print head has died! Before you go trashing the printer or buying a new one try some of the following suggestions.
Acadecraft is one of the dominant elearning content providers. It aids different organizations and institutions achieve their dream status with efficient and accurate content. The best part of about the company is that it always follows the clients’ guidelines. Bringing customized services to the threshold is the specialty of the company.
ReplyDeleteVirtual instructor-led training content provider
Avail Expert homework help United States and make things easy for yourself. Connect with Academic Writers & never miss an homework deadline. Subject-Wise homework Help In USA.
ReplyDeleteNice content thanks for sharing with Us. If you are facing any issues with your Gmail app or website? Do not worry, follow the tips to fix the Fix Gmail Not working issues. You may need to reinstall your Gmail mobile app.
ReplyDeleteHow to fix Gmail forward not working?
ReplyDeleteIf your Gmail forward not working, there are possibilities that you might have disabled the Gmail forwarding feature. In such cases, you have to enable it again. For that, log into your Facebook account and go to Settings. Select Settings and open the “Forwarding and POP/IMAP” tab. Now, enter a Forwarding email address and then click Next to confirm. A pop-up window will open. Click Proceed to confirm the forwarding email address. A confirmation link will now be sent to the forwarding address. Click on the link for approving the forwarding settings. Refresh the Gmail interface and in the “Forwarding” section, select the “Forward a copy of incoming mail to” option. Select the option what Gmail should do with the forwarded emails and click on Save changes.
Also Read:-
Outlook Search Not Working
Change Email Signature in Outlook
Recall an Email in Outlook 2016
Move Outlook Emails to Gmail
Uninstall Outlook On Windows 10
Change Outlook Password on iPhone
Thanks for sharing the valuable information with Us. Are you also looking for how do I reset my AOL Mail settings? If yes! Then follow the steps that we have concluded here: 1. To update your AOL Mail settings
ReplyDeleteThanks for sharing the valuable information with us. Are you looking for how to wake up Brother Printer from sleep? If yes! Then approach the steps that are mentioned below: 1. Visit the control panel on your Brother printer.
ReplyDeleteThanks for sharing such a nice article Is your HP Printer offline? You can get it back online by tapping on the Start menu of your device > Printer and Devices > Printers > uncheck “Use the offline mode”
ReplyDeleteIf still the Canon printer printing blank pages, reinstall the driver by following steps:
ReplyDelete1. Go to the control panel and open 'Programs and Features' and search for your printer driver.
2. Right click on the driver software and tap on Uninstall.
3. Restart your system and download printer driver again from www.canon.com/ijsetup
Hyderabad escorts
ReplyDeleteBanjara hills escorts
Bagi yang mengalami masalah dalam hal mengunduh video, ada banyak cara download video di Twitter yang bisa Kamu terapkan dengan mudah, baik di smartphone Android maupun perangkat komputer.
ReplyDeletegoogle 888
ReplyDeletegoogle 889
google 890
google 891
google 892
google 893
google 894
Nice content thanks for sharing with Us. If you are facing HP Laptop Cooling Fan Error? while you turn on your laptop? Well, to fix this issue, you may reset your BIOS or run a self-diagnostic test on your laptop.
ReplyDeleteThanks for Sharing with Us.If your laptop is actually plugged in and yet it is still not charging, the battery might be the culprit. If so, learn about its integrity. If it's removable. Learn the resolution steps and measures to fix the issue of the HP laptop plugged in but not charging to get immediate aid as and when needed.
ReplyDeleteDo you want antivirus software protection against the cyber threats? We are offering best antivirus software plans. Our antivirus software protects against the last virus, and malware etc.
ReplyDeleteantivirus
antivirus software
:Can I get home broadband without a contract?
ReplyDeleteYou can get fast, reliable broadband in your home without linking yourself to a long-term contract. But your choice of providers is relatively restricted.
broadband without phone line no contract
no contract broadband without landline
Thanks for sharing the valuable information with us. Want to install HP Solution Center on your Windows or Mac device? Learn how it is done and use the software to order ink supplies, check ink levels, and more.
ReplyDeleteThanks for sharing with Us. Learn the quick and easy-to-follow method to redeem Xbox digital code from Amazon. You can avail all the exciting gaming deals with it. or visit amazon.com/redeem
ReplyDeleteHi, your content is very unique and informative, Keep spreading this useful information. Meanwhile, Emirates Airlines Office Nepal is one among the most youthful inside the world, construing that close by unprecedented assistance and inflight amusement, pioneers can recognize as far as possible in solace and in this manner the most recent in hold up course of action paying little mind to where they're masterminded. Their story began in 1985 once we dispatched practices with only two plane
ReplyDeleteFIFO Calculator, first in-first out, means the items that were bought first are the first items sold.
ReplyDeleteEnding inventory is valued by the cost of items most recently purchased. First-In,
First-Out method can be applied in both the periodic inventory system and the perpetual inventory system.